训练数据和批处理
我们在标准WMT 2014英语德语数据集上进行了训练,该数据集包含约450万个句子配对。句子使用字节对编码[3]进行编码,该编码具有共享源-目标词汇约37000个令牌。对于英语-法语,我们使用了明显更大的WMT2014年英法数据集,由3600万个句子和32000个单词组成词汇[31]。句子对按大致的序列长度分组在一起。每次培训该批包含一组句子对,其中包含约25000个源令牌和25000个目标令牌。
正则化
我们在训练过程中采用了三种正则化方法:
Residual Dropout
我们将dropout[27]应用于每个子层的输出,然后再将其添加到子层输入和归一化。此外,我们将dropout应用于嵌入和编码器和解码器堆栈中的位置编码。对于基本模型,我们使用以下比率Pdrop = 0.1.
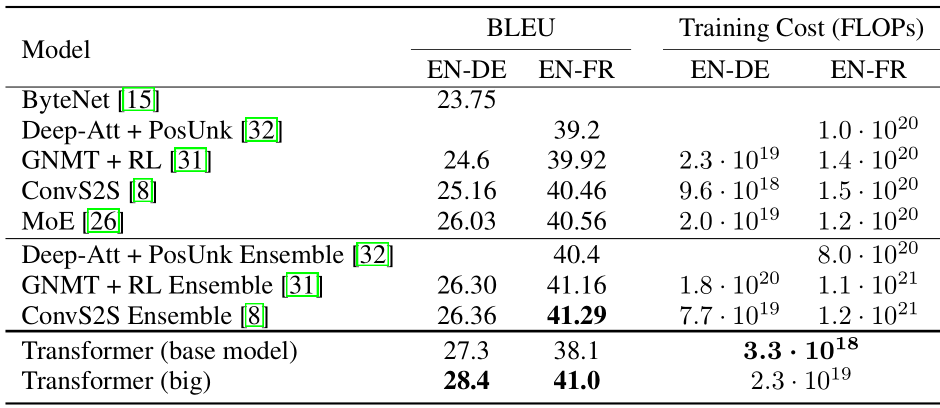
表2:Transformer在BLEU方面的得分高于之前最先进的模型英语到德语和英语到法语的newstest2014测试只需培训成本的一小部分